What does digital democracy mean to you?
I presented this poster: Rethinking Digital Democracy v4 at the Social Media and Society conference last weekend, and it demonstrated only one of many images of digital democracy.
Digital democracy was portrayed at this conference as:
having a voice in the local public square (Habermas)
making local leadership directly accountable to constituents
having a voice in an external public sphere via international media sources
coordinating or facilitating a large scale protest movement
the ability to generate observable political changes
political engagement and/or mobilization
a working partnership between citizenry, government and emergency responders in crisis situations
a systematic archival of government activity brought to the public eye. “Archives can shed light on the darker places of the national soul”(Wilson 2012)
One presenter had the most systematic representation of digital democracy. Regarding the recent elections in Nigeria, he summarized digital democracy this way: “social media brought socialization, mobilization, participation and legitimization to the Nigerian electoral process.”
Not surprisingly, different working definitions brought different measures. How do you know that you have achieved digital democracy? What constitutes effective or successful digital democracy? And what phenomena are worthy of study and emulation? The scope of this question and answer varies greatly among some of the examples raised during the conference, which included:
citizens in the recent Nigerian election
citizens who tweet during a natural disaster or active crisis situation
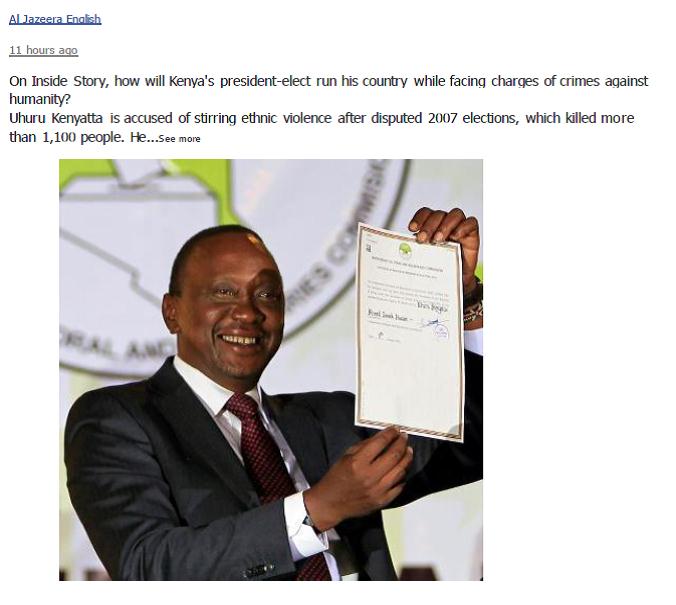
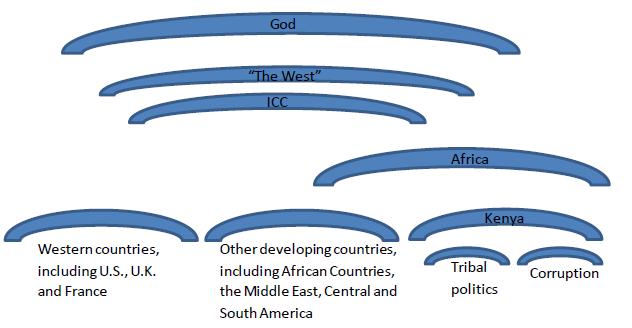
citizens who changed the international media narrative regarding the recent Kenyan elections and ICC indictment
Arab Spring actions, activities and discussions
“The power of the people of greater than the people in power” a perfect quote related to Arab revolutions on a slide from Mona Kasra
the recent Occupy movement in the US
tweets to, from and about the US congress
and many more that I wasn’t able to catch or follow…
In the end, I don’t have a suggestion for a working definition or measures, and my coverage here really only scratches the surface of the topic. But I do think that it’s helpful for people working in the area to be aware of the variety of events, people, working definitions and measures at play in wider discussions of digital democracy. Here are a few question for researchers like us to ask ourselves:
What phenomenon are we studying?
How are people acting to affect their representation or governance?
Why do we think of it as an instance of digital democracy?
Who are “the people” in this case, and who is in a position of power?
What is our working definition of digital democracy?
Under that definition, what would constitute effective or successful participation? Is this measurable, codeable or a good fit for our data?
Is this a case of internal or external influence?
And, for fun, a few interesting areas of research:
There is a clear tension between the ground-up perception of the democratic process and the degree of cohesion necessary to affect change (e.g. Occupy & the anarchist framework)
Erving Goffman’s participant framework is also further ground for research in digital democracy (author/animator/principal <– think online petition and e-mail drives, for example, and the relationship between reworded messages, perceived efficacy and the reception that the e-mails receive).
It is clear that social media helps people have a voice and connect in ways that they haven’t always been able to. But this influence has yet to take any firm shape either among researchers or among those who are practicing or interested in digital democracy.
I found this tweet particularly apt, so I’d like to end on this note:
“Direct democracy is not going to replace representative government, but supplement and extend representation” #YES #SMSociety13
— Ray MacLeod (@RayMacLeod) September 14, 2013