
I recently transitioned from my study of the many reasons why the voice of DC taxi drivers is largely absent from online discussions into a study of the powerful voice of the Kenyan people in shaping their political narrative using social media. I discovered a few interesting things about digital democracy and social media research along the way, and the contrast between the groups was particularly useful.
Here are some key points:
- The methods of sensemaking that journalists use in social media is similar to other methods of social media research, except for a few key factors, the most important of which is that the bar for verification is higher
- The search for identifiable news sources is important to journalists and stands in contrast with research methods that are built on anonymity. This means that the input that journalists will ultimately use will be on a smaller scale than the automated analyses of large datasets widely used in social media research.
- The ultimate information sources for journalists will be small, but the phenomena that will capture their attention will likely be big. Although journalists need to dig deep into information, something in the large expanse of social media conversation must capture or flag their initial attention
- It takes some social media savvy to catch the attention of journalists. This social media savvy outweighs linguistic correctness in the ultimate process of getting noticed. Journalists act as intermediaries between social media participants and a larger public audience, and part of the intermediary process is language correcting.
- Social media savvy is not just about being online. It is about participating in social media platforms in a publicly accessible way in regards to publicly relevant topics and using the patterned dialogic conventions of the platform on a scale that can ultimately draw attention. Many people and publics go online but do not do this.
The analysis of social media data for this project was particularly interesting. My data source was the comments following this posting on the Al Jazeera English Facebook feed.
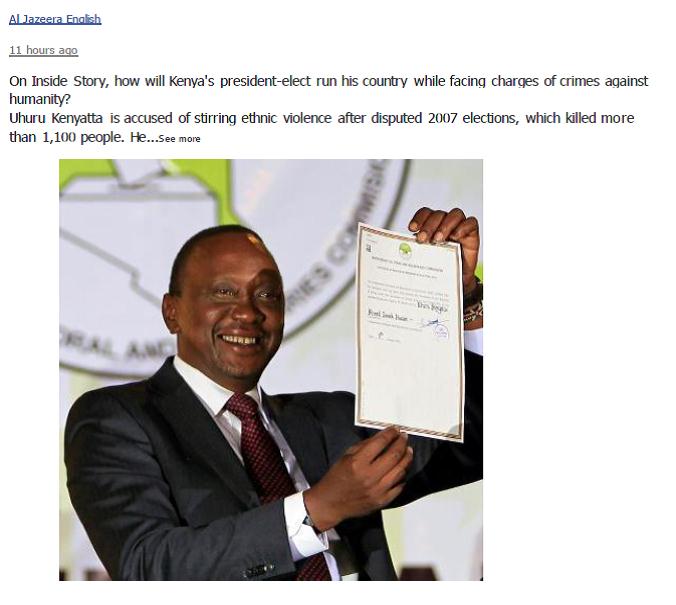
It evolved quite organically. After a number of rounds of coding I noticed that I kept drawing diagrams in the margins of some of the comments. I combined the diagrams into this framework:
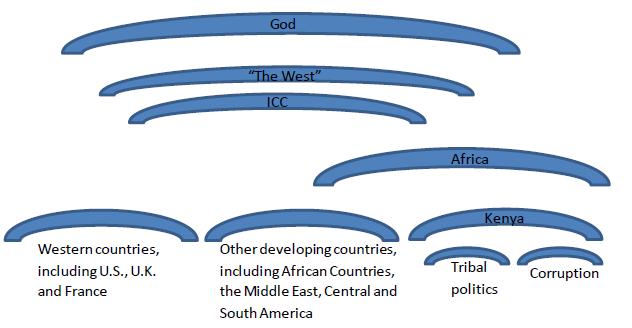
Once this framework was built, I looked closely at the ways in which participants used this framework. Sometimes participants made distinct discursive moves between these levels. But when I tried to map the participants’ movements on their individual diagrams, I noticed that my depictions of their movements rarely matched when I returned to a diagram. Although my coding of the framework was very reliable, my coding of the movements was not at all. This led me to notice that oftentimes the frames were being used more indexically. Participants were indexing levels of the frame, and this indexical process created powerful frame shifts. So, on the level of Kenyan politics exclusively, Uhuru’s crimes had one meaning. But juxtaposed against the crimes of other national leaders’ Uhuru’s crimes had a dramatically different meaning. Similarly, when the legitimacy of the ICC was questioned, the charges took on a dramatically different meaning. When Uhuru’s crimes were embedded in the postcolonial East vs West dynamic, they shrunk to the degree that the indictments seemed petty and hypocritical. And, ultimately, when religion was invoked the persecution of one man seemed wholly irrelevant and sacrilegious.
These powerful frame shifts enable the Kenyan public to have a powerful, narrative changing voice in social media. And their social media savvy enables them to gain the attention of media sources that amplify their voices and thus redefine their public narrative.







